Internet est à un tournant. L'augmentation constante du nombre d'annonces publicitaires a mis fin au modèle de revenu qui repose uniquement sur les revenus publicitaires pour exploiter des sites Web et des entreprises.
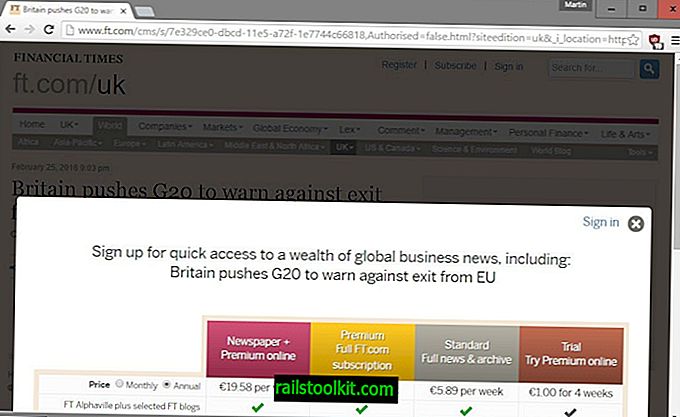
Les sites de nouvelles ont commencé à expérimenter différentes manières de diversifier leurs sources de revenus. Le système de mur payant est une option importante que des sites tels que le Wall Street Journal, le Financial Times, le New York Times ou le Washington Post ont mis en œuvre.
Il existe différents types de paywalls, mais ils ont tous en commun de bloquer l'accès au contenu directement ou après la lecture d'un certain nombre d'articles sur le site.
Les visiteurs sont ensuite invités à s'abonner au site pour continuer à lire des articles à ce sujet.
Cela peut sembler logique du point de vue commercial et être plus lucratif que de lutter contre les utilisateurs qui exploitent des bloqueurs de publicités, mais cela présente un inconvénient, à la fois pour le site à mur payant et pour l'utilisateur bloqué.
Les sites perdent un pourcentage élevé de visiteurs s’ils mettent en place un système de mur payant. Le pourcentage réellement élevé n'est pas clair et varie probablement d'un site à l'autre, mais il est probablement beaucoup plus élevé que le pourcentage de visiteurs abonnés au site après s'être vu offrir le choix de s'abonner pour lire l'article souhaité.
Masquerade votre navigateur
Ce n’est un secret pour personne que les sites d’information permettent l’accès aux agrégateurs de nouvelles et aux moteurs de recherche. Si vous consultez Google Actualités ou Recherche par exemple, vous y trouverez des articles de sites contenant des paywalls.
Dans le passé, les sites d’information permettaient aux visiteurs d’agréger des informations telles que Reddit, Digg ou Slashdot d’accéder aux visiteurs, mais cette pratique semble aujourd’hui comme morte.
Une autre astuce, coller le titre de l’article dans un moteur de recherche pour lire directement l’histoire mise en cache, ne semble plus fonctionner correctement, de même que les articles sur les sites avec des paywalls ne sont généralement plus mis en cache.
Mise à jour : le Wall Street Journal a annoncé qu’il allait boucher le trou décrit ci-dessous. Vous pouvez toujours lire des articles derrière le paywall du site en utilisant la méthode suivante:
- Appuyez sur F12 lorsque vous êtes sur la page d'article avec l'article coupé et sur la demande d'abonnement pour le lire en entier.
- Ouvrez l'onglet console.
- Coller javascript: window.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Appuyez sur Entrée.
La page doit être rechargée et l'article doit être chargé dans son intégralité. Vous pouvez également publier le lien de l'article sur Facebook, par exemple dans un nouveau message que vous seul pouvez voir. En cliquant sur le lien affiché, l'article devrait être entièrement chargé sur le site Web du Wall Street Journal.
Agent utilisateur et référent
Vous vous demandez probablement comment les sites bloquent ou autorisent l'accès au contenu du site. Les méthodes se sont améliorées au fil des ans et il ne suffit plus de changer le référent du navigateur en //www.google.com/ pour obtenir un accès complet au contenu d'un site.
Au lieu de cela, les sites utilisent diverses vérifications, notamment un agent utilisateur, un référent et des cookies, et parfois même plus, pour déterminer la légitimité de l'accès.
informations générales
Le meilleur moyen de masquer le navigateur est probablement de le faire apparaître comme étant Googlebot.
- Referrer: //www.google.com/
- Agent utilisateur: Mozilla / 5.0 (compatible; Googlebot / 2.1; + // www.google.com/bot.html
Firefox
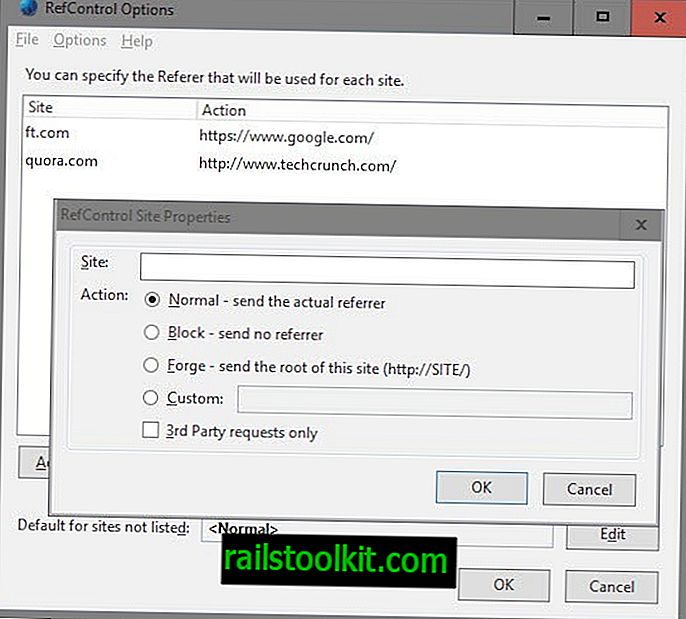
Les utilisateurs de Firefox ont besoin de deux add-ons de navigateur pour cela: le premier, RefControl, pour modifier la valeur du référent lors de la visite de sites d'informations, le second, User Agent Switcher, pour changer l'agent utilisateur du navigateur.
- Téléchargez et installez les deux extensions dans le navigateur Web Firefox.
- Tapez sur la touche Alt, puis sélectionnez Outils> Options RefControl.
- Cliquez sur "ajouter un site", entrez un nom de domaine sous le site, sélectionnez une action personnalisée, puis entrez //www.google.com/ en tant que référent.
- Répétez cette opération pour tous les sites d'actualités auxquels vous souhaitez accéder (certains risquent de ne pas fonctionner même si vous apportez les modifications, gardez cela à l'esprit).
- Lorsque vous avez terminé, fermez la fenêtre de configuration.
- Appuyez de nouveau sur la touche Alt, puis sélectionnez Outils> Agent d'utilisateur par défaut> Modifier les agents d'utilisateur dans le menu.
- Sélectionnez Nouveau> Agent utilisateur et remplacez la chaîne dans le champ Agent utilisateur par Mozilla / 5.0 (compatible; Googlebot / 2.1; + // www.google.com/bot.html). Nommez-le Googlebot.
- Quittez le menu.
- Avant d'accéder à ces sites, appuyez sur Alt, puis sélectionnez Agent d'utilisateur par défaut> Googlebot.
C'est tout ce qu'il y a à faire. Il est un peu regrettable qu’il n’y ait pas d’extension pour Firefox permettant de changer automatiquement l’agent utilisateur en fonction des sites visités.
Google Chrome
Les utilisateurs de Google Chrome peuvent installer des extensions, telles que User Agent Switcher et Referer Control, disponibles pour le navigateur.
Il existe toutefois une autre possibilité, à savoir la création d'une extension personnalisée qui automatise le processus dans le navigateur.
Les instructions sont fournies sur Elaineou. En gros, il suffit de créer un nouveau répertoire sur l’ordinateur local, de créer les deux fichiers background.js et manifest.json qu’il contient, puis de copier et coller le code trouvé sur le site dans les fichiers.
Vous devez activer le "mode développeur" sur chrome: // extensions /, puis sélectionner "charger une extension décompressée" pour choisir le dossier dans lequel vous avez créé les deux fichiers afin de charger l'extension dans Chrome.
Vous pouvez modifier la liste des sites qu’il supporte pour en ajouter de nouveaux.